|
— jeremy's account — |

|
|
How I Cracked the Golem Script by Jeremy Brown 
|
|
I'm currently a web applications programmer at Biola University, my alma mater. I have an MA in
Applied Linguistics. My wife and I are starting the
process of transitioning to Bible translation work. I don't have much
experience with decipherment - I probably did
some easy examples when I was a kid, and I did do a short paper on the
history of encrypting texts when I was getting my MA. When I was an
undergrad, I took 4 semesters of Biblical Hebrew. That, I think, is what
helped me the most in discovering the solution to this puzzle. |
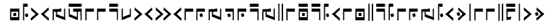
"Half of man's wisdom is knowing where it ends." |
|
I decided I should give it a try. There was a Rosetta Stone, which I
thought gave me a chance of success. Trying to decode something without a
plaintext correlated with it could be orders of magnitude harder, and I
don't think I would have gotten far if it weren't for the English text. |
|
"Half of man's wisdom is knowing where it ends." |
|
I thought the English text might be some kind of a clue. I had a number of ideas: |
|
|
|
The little scroll which is posted in the forums, and the "reverse" of the scroll text, confirmed that >< was one character, and not two. |
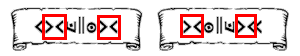
|
|
My second key achievement was to correctly guess the letter i. The characters with lines over them reminded me of the vowels in Hebrew, which are lines and dots that go over and under characters to provide the vowel sound. I looked and saw that the most frequent vowel in the English text was i, with 4 occurrences, and the most frequent "overlined" character also had 4 occurrences. I tried that out, and the i's in English read left-to-right seemed to match the relative positions in the text as the overlined character in the Script. None of the other characters with lines over them seemed to match the relative position of a vowel in the English text, though, so I decided the lines by themselves weren't relevant. |
|
"Half of man's wisdom is knowing where it ends." |
|
My third key decision was to compare character counts in English and Script. I tried counting other frequent characters in the English text: s - 4, n - 4, i - 4, e - 3, o - 3, w - 3, m - 2, d - 2, h - 2. I noticed that one character repeated itself surrounding a single character in the Script: the sequence: >< > ><. I looked for a similar sequence in the English text and found the "ere" in "where", so I thought I could possibly identify >< with e. The only problem was that e also occurs as the fourth character to the end in English, but >< only occurs third to the end in Script. It also made sense that the little "word of creation" scroll in the forum might have a couple of e's in it, since it needed some vowels. |
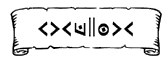
|
|
Based on the character count and on the relative positions in the two texts (mirrored positions though, since they read opposite directions), I was able to correctly guess the assignment for i, n, s, d, w and a. "e" was also correctly assigned. At that point I had something like this: |
| dsen???i?e?e?wn?win???ism?d?is?wnsma???????a |
|
I had some of the letters in the same general area (reversed) as in the English text. But the words were switched around. Somewhere in here, it dawned on me what was happening: the Script was written right-to-left, but each word in that order was scrambled up some. After I looked at it a while, the answer finally dawned on me. In a way, the text is written half one way and half the other. The message is read right-to-left, but each pair of characters is read left-to-right! |
|
I started drawing lines between the letters I knew: |
| ds|en|??|?i|?e|?e|?w|n?|wi|n?|??|is|m?|d?|is|?w|ns|ma|??|??|??|?a |
|
When read right-to-left, but in every segment left-to-right, the above line can be transliterated to read like normal English, that is left-to-right: |
| ?a??????mans?wisd?m?is??n?win??w?e?e?i??ends |
|
Probably if I had done a transformation like the one above on paper, instead of just in my head, I could have seen the remaining issues easier. At this point it was pretty easy to identify o and f and the g in knowing. The first line below shows the original, the second line is in English order. |
|
ds|en|??|?i|?e|re|?w|ng|wi|no|??|is|m?|do|is|?w|ns|ma|f?|?o|?f|?a ?a?f?of?mans?wisdom?is??nowing?wre?e?i??ends |
|
I had scribbled in an r between the two e's (marked in red above), and because of that I misidentified h. I eventually realized that the r was really the h, and then I was able to make: |
| ha?f?of?mansw?isdom?is??nowing?where?i??ends |
|
Only later I realized that the Script character that looks like a lowercase r was a "space". At that time I thought it was a "null" character, a placeholder to keep two letters from two different words from the same two-character segment. I started putting X's in those spaces. |
| HalfXofXmansXwisdomXisXknowingXwhereXitXends |
|
I was excited at this point that I had managed to figure it out. This was after 3 hours of work. |

|
|
Next I started working on applying the code to the new text. The first line, "Wisdom has built her house", went pretty easily. I came across the first new characters at b and u in the word built. |

|
|
I made a correspondence chart at the bottom of the page, and wrote the unknown Script and English letters over on the side. |

|
|
The next line was harder. There were several characters I didn't know,
and couldn't guess right away. So after I'd written down all the
characters I knew, I started on line 3, where I figured out p and c in
"A prudent man conceals knowledge." |

|
|
With the thrill of victory pulsing through my veins, I sent an email to
Greg, and hoped someone hadn't beaten me to the solution.
The entire time to solve was probably 4 1/2 hours of continuous work.
The next day, I got an email from Greg, confirming my success. And it
sounds like there is still more fun to be had! |
|
Jeremy was kind enough to write a small Java generator which you can use to write your own messages in the ancient script! |